Google Sheets is a great tool for storing not too large amount of data, with possibility of easy adding and editing data manually without deep technical knowledge of SQL or programming. On the other hand Google offers a BigQuery – a big data warehouse with super-fast SQL wich allows to manipulate and analyse huge amount of data in efficient manner. Despite that differences – importing data from Google Sheets into BigQuery is a quite popular need because you might want to import manually provided data from Sheets in order to join them with your BigQuery tables. So that’s are the steps that will allow you to do that using Python and Google APIs:
- Create Google service account for Google APIs authentication
- Get data from Google Sheets to Pandas DataFrame using gspread_pandas library
- Import Pandas DataFrame into BigQuery using pandas_gbq library
1. Create Google service account for Google APIs authentication
Log into your Google Cloud Platform account: https://console.cloud.google.com/
Create GCP project if you don’t have any and go to Credentials section:
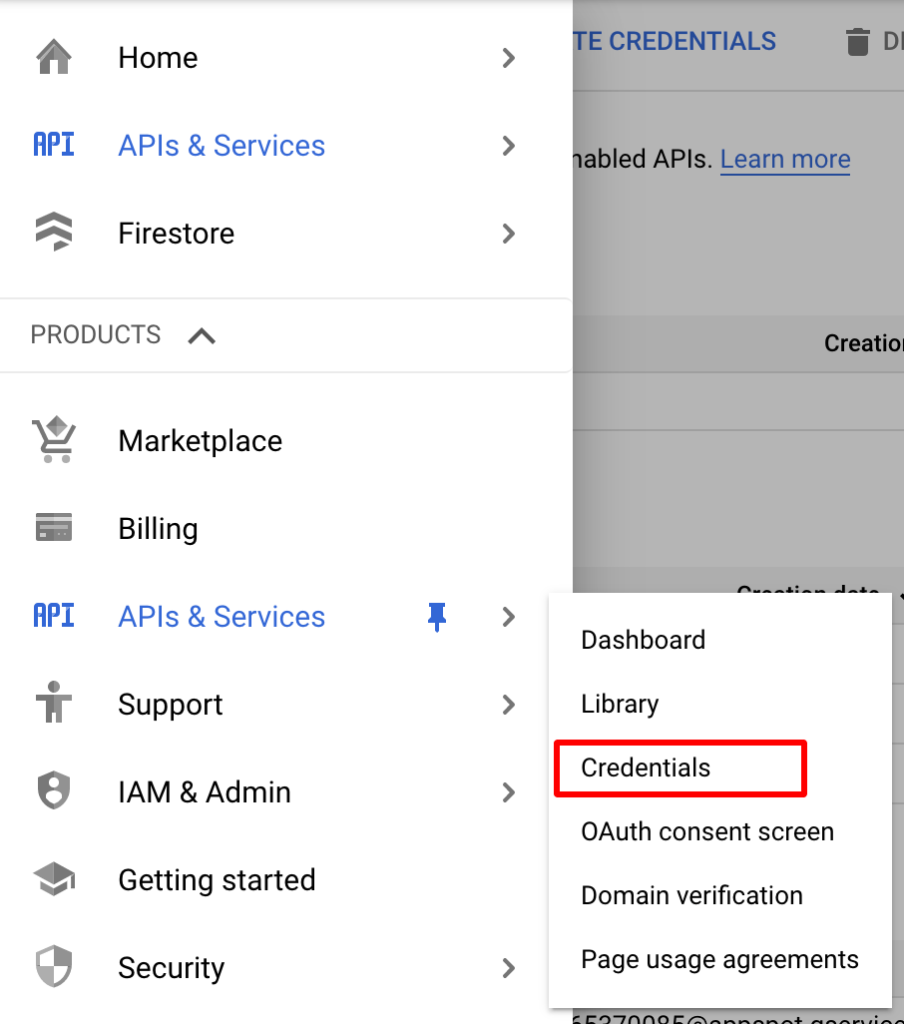
Click “Create credentials” and select “Service account” option:
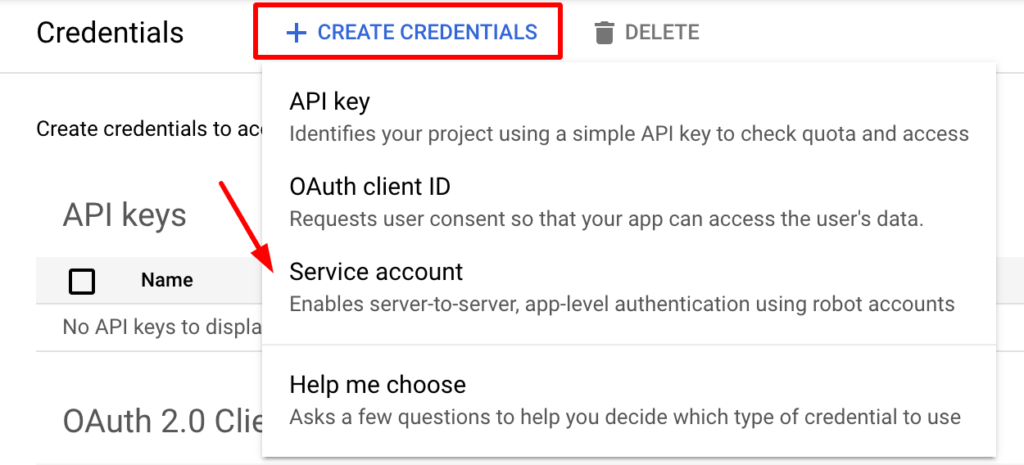
Then give your service account a name and give it an BigQuery Admin role and click “Done”:
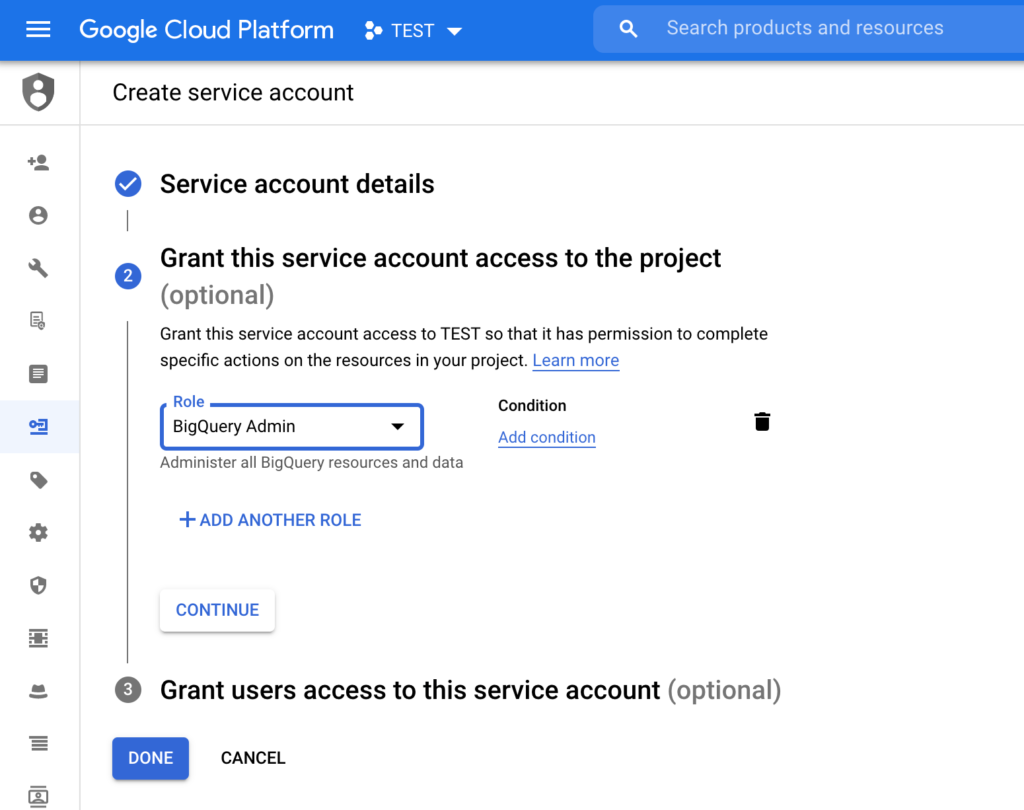
When the service account is created – click on it and generate a JSON key (we will use it later in our Python script for authentication):
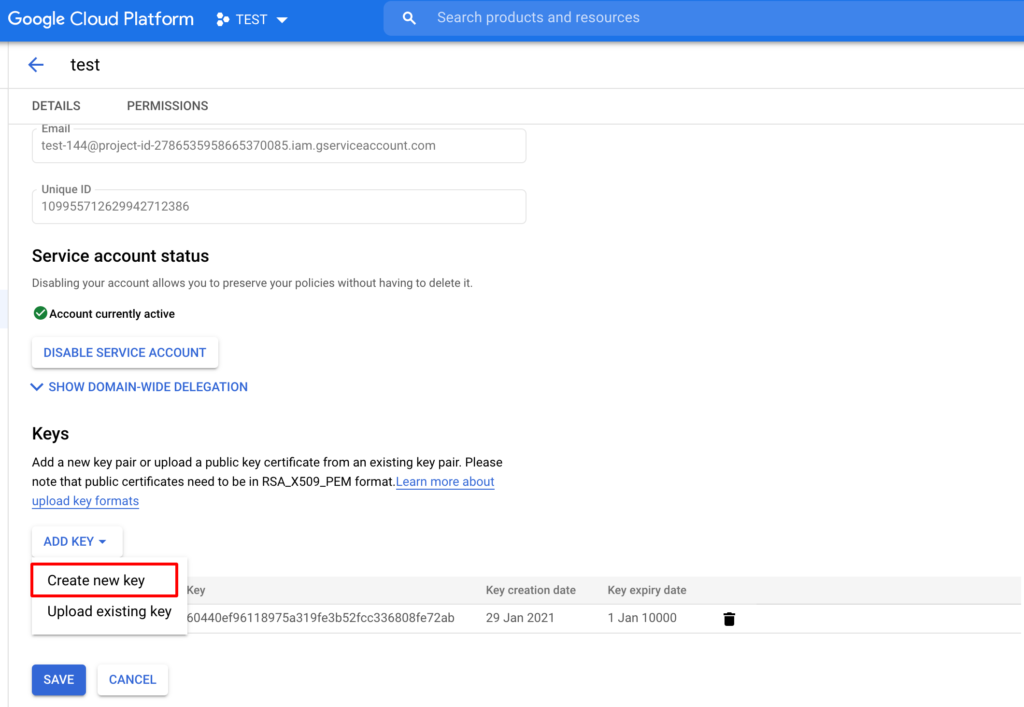
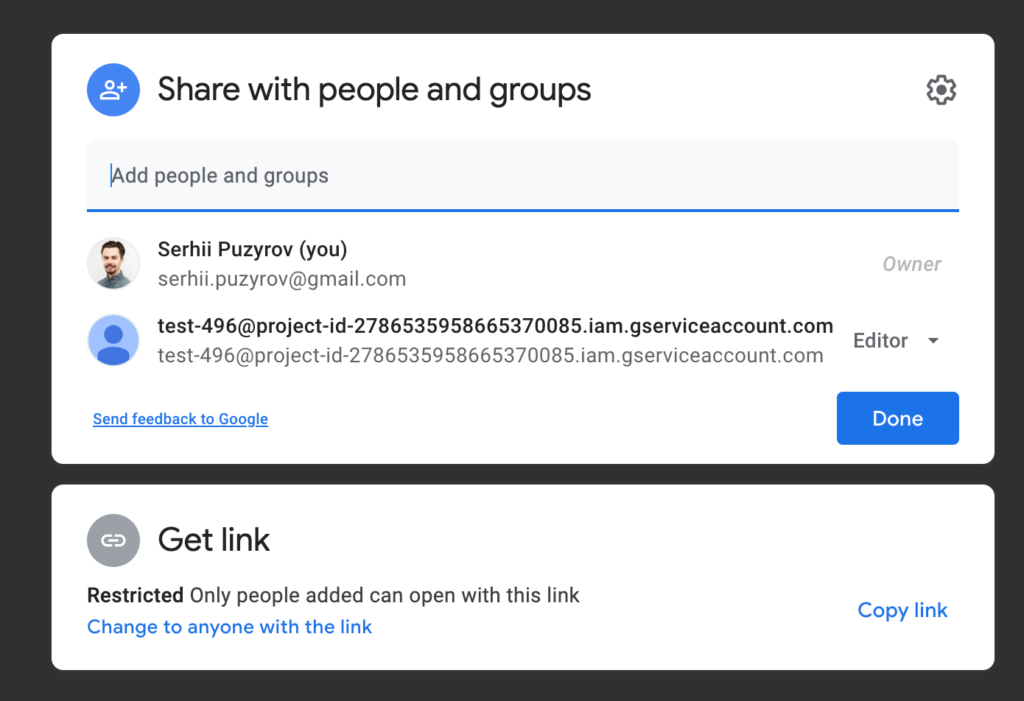
You service account should have an email, something similar to this:
test-496@project-id-2786535958665370085.iam.gserviceaccount.com
You should share your Spreadsheet to this email like to regular user so you will have access to it using API:
2. Get data from Google Sheets to Pandas DataFrame using gspread_pandas library
Install gspread_pandas library using PIP or by adding it to your requirements.txt. This is how the whole code looks like:
from gspread_pandas import Spread, conf
import os
# spreadsheet ID (or name) and sheet name
spreadsheet_id = 'your value'
sheet_name = 'your value'
# get current directory
current_dir_path = os.path.dirname(os.path.realpath(__file__))
# authentication
c = conf.get_config(current_dir_path, 'google_secrets.json')
spread = Spread(spreadsheet_id, config=c)
# get dataframe
df = spread.sheet_to_df(sheet=sheet_name, start_row=1).reset_index()
print(df)You only should paste your spreadsheet ID (or spreadsheet name) and sheet’s name to this code. Also paste your Google service account secret into your working directory and rename it to google_secrets.json for example. After running this code – should get your data from Google Sheet as a Pandas DataDrame printed.
3. Import Pandas DataFrame into BigQuery using pandas_gbq library
Install pandas_gbq library using PIP or by adding it to your requirements.txt. This is how the whole code looks like:
import pandas_gbq
import os
import re
# your GCP project ID and GBQ destination table in format dataset.table
project_id = 'your value'
destination_table = 'your value'
# get current directory
current_dir_path = os.path.dirname(os.path.realpath(__file__))
# import credentials for BigQuery API authentication
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = current_dir_path + '/google_secrets.json'
# function that will remove characters that are nor allowed by BigQuery in names of columns
def column_names_normalize(df):
for col_name in df:
all_except_letters = re.sub(r"([?!^a-zA-Z]+)", "_", col_name)
remove_chars_at_beginning = col_name.lstrip(all_except_letters)
new_col_name = re.sub(r"[^0-9a-zA-Z]+", "_", remove_chars_at_beginning)
df.rename(columns={col_name: new_col_name}, inplace=True)
return df
df = column_names_normalize(df)
print(df)
# upload data to BigQuery
pandas_gbq.to_gbq(df, destination_table, project_id, if_exists='replace')Remember to paste your GCP project ID and BigQuery table path (for example: dataset.table) into the code. Create dataset manually before running the script, but the table will be created by itself.
Complete script that will import data from Google Sheets to BigQuery
As a result you should get your DataFrame to your BigQuery. The whole code with both Google Sheets and BigQuery parts should be this:
from gspread_pandas import Spread, conf
import pandas_gbq
import os
import re
# spreadsheet ID and sheet name
spreadsheet_id = 'your value'
sheet_name = 'your value'
# your GCP project ID and GBQ destination table in format dataset.table
project_id = 'your value'
destination_table = 'your value'
# get current directory
current_dir_path = os.path.dirname(os.path.realpath(__file__))
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = current_dir_path + '/google_secrets.json'
c = conf.get_config(current_dir_path, 'google_secrets.json')
spread = Spread(spreadsheet_id, config=c)
# get dataframe
df = spread.sheet_to_df(sheet=sheet_name, start_row=1).reset_index()
# function that will remove characters that are nor allowed by BigQuery in names of columns
def column_names_normalize(df):
for col_name in df:
all_except_letters = re.sub(r"([?!^a-zA-Z]+)", "_", col_name)
remove_chars_at_beginning = col_name.lstrip(all_except_letters)
new_col_name = re.sub(r"[^0-9a-zA-Z]+", "_", remove_chars_at_beginning)
df.rename(columns={col_name: new_col_name}, inplace=True)
return df
df = column_names_normalize(df)
print(df)
# upload data to BigQuery
pandas_gbq.to_gbq(df, destination_table, project_id, if_exists='replace')Optionally you can automate those kind of imports if you will host that script on some virtual machine and will schedule it using cron for example. You can also check out some ready-to-use tools that will do that kind of automated imports for you – for example Pipelinica tool.
