Regular expressions are great helpers for every data analyst because they allows to transform dimensions applying quite complicated logic rules. In Google Data Studio I often use REGEXP text functions – so I decided to share with you some my most often use cases. In addition – we’ll find out the difference between REGEXP_REPLACE, REGEXP_EXTRACT and REGEXP_MATCH based on examples.
REGEXP_REPLACE – is often used for text cleaning. It replaces values that matches our rule to any other value we want. For example we want to remove symbols “-“, “_” and numbers from our text. We can do it by applying this regex:
REGEXP_REPLACE(raw_text, "-|_|[0-9]", "")It says: “Find all _, -, and numbers, and replace it with empty text”. This is what we’ll get in result:

Another case – for example we want to get the part of text before the dash. We could use REGEXP_EXTRACT but also it can be done with REGEXP_REPLACE:
REGEXP_REPLACE(raw_text, "- .*", "")
It says: “Get all text after “- ” and replace it with empty text”. As you can see – combination of symbols “.*” means “everything”.
REGEXP_EXTRACT – is used for extracting data that matches our rule. For example we want to extract the domain name from url which have this pattern:
https://serhiipuzyrov.com/contact/
We can use this formula in order to do that:
REGEXP_EXTRACT(URL, "//(.*?)/")With this regex we say something like: “Get all text between // and the first occurrence of /”. This is how this regex affects different types of links in Data Studio:
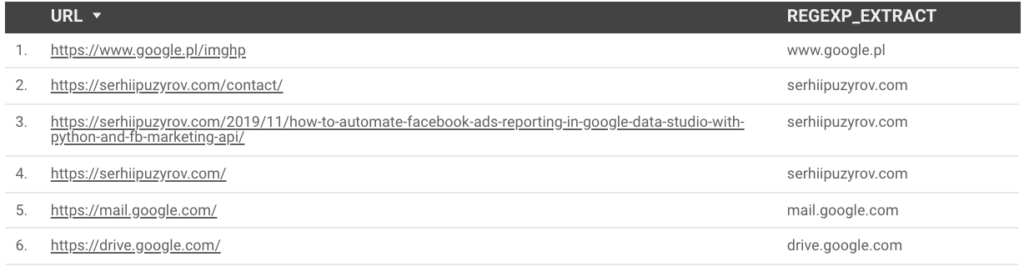
Another use case – we have a solid text “first|second|third” which we want to split on separate dimensions: “first”, “second” and “third”.
In order to do that – we can use this formulas:
REGEXP_EXTRACT(regex orig, "(.*)\\|.*\\|.*") #first
REGEXP_EXTRACT(regex orig, ".*\\|(.*)\\|.*") #second
REGEXP_EXTRACT(regex orig, ".*\\|.*\\|(.*)") #third
Some of them can be written shorter, but I want you to see visually the difference between these three formulas. As you can see – we only changing the position of (.*) – this way we let regex know which logical part of text we want to extract.
Symbols “\\” – helps us to transform special characters to usual text, so in formulas above we let regex know that “|” is not a logical operator “or”, but a simple text. It usually called the escape character, and it may differ a bit in regular expressions of different languages/environments. In case of Google Data Studio it’s two backslash characters \\.
REGEXP_MATCH – function that returns True when text matches the rule, or False if not. For example we want to know if given word contains letter n – we can use this regex formula for that:
REGEXP_MATCH(raw_text, ".*n.*")
With symbols “.*” we say that there can be anything before and after “n”.
REGEXP_MATCH is often used in Data Studio case formulas for dimensions grouping. This is an example of such formula which copies Google Analytics Default Channel Grouping:
CASE
WHEN ((Source="direct" AND Medium="(not set)") OR Medium="(none)") THEN "Direct"
WHEN Medium="organic" THEN "Organic Search"
WHEN (Social Source Referral="Yes" OR REGEXP_MATCH(Medium,"^(social|social-network|social-media|sm|social network|social media)$")) THEN "Social"
WHEN Medium="email" THEN "Email"
WHEN Medium="affiliate" THEN "Affiliates"
WHEN Medium="referral" THEN "Referral"
WHEN (REGEXP_MATCH(Medium,"^(cpc|ppc|paidsearch)$") AND Ad Distribution Network!="Content") THEN "Paid Search"
WHEN REGEXP_MATCH(Medium," ^(cpv|cpa|cpp|content-text)$") THEN "Other Advertising"
WHEN (REGEXP_MATCH(Medium,"^(display|cpm|banner)$") OR Ad Distribution Network="Content") THEN "Display" ELSE "(Other)"
ENDYou can read more about Data Studio case formulas in my article:
https://serhiipuzyrov.com/2019/01/case-statements-in-google-data-studio/
Hope my examples will help you to understand regex text formulas in Google Data Studio better. I encourage you to get familiar with them and I promise – they will save you lots of time and will take your dashboards to the new level.

Some more good regex: extract before some symbol, but it’s optional:
REGEXP_EXTRACT(‘delete|get this*test’, ‘\\|(.*?)(?:\\*|$)’)
will get “get this” text before *, but that symbol is optional.